
InOutDoorPeople RGB-D Dataset
The dataset contains the rgb and depth data, together with the annotations and camera calibration file to create the original point clouds.
Oier Mees, Andreas Eitel, Abhinav Valada, Wolfram Burgard
Our approach learns how to best combine different sensor modalities to handle sensor noise induced by dynamic environments such as lighting changes, out of range readings in the depth sensor and motion blur among others.
Object detection and scene segmentation are an essential task for autonomous robots operating in dynamic and changing environments. A robot should be able to detect objects and do semantic segmentation in the presence of sensor noise that can be induced by changing lighting conditions for cameras and false depth readings for range sensors, especially RGB-D cameras. To tackle these challenges, we propose a novel adaptive fusion approach for object detection and segmentation that learns weighting the predictions of different sensor modalities in an online manner. Our approach is based on a mixture of convolutional neural network (CNN) experts and incorporates multiple modalities including appearance, depth and motion. To learn more, see the Technical Approach section.
Mixture of Deep Experts For Object Detection
We present a novel adaptive multimodal fusion approach, based on a mixture of convolutional neural network (CNN) models that can be used in robotic applications, such as object detection or segmentation. Our approach has been developed for robots that have to operate in changing environments, which affects sensor noise. For example robots that have to operate in both, a dark indoor and a bright outdoor scenario, during different times of the day, or under different weather conditions in the case of autonomous cars. The approach is being developed by members from the Autonomous Intelligent Systems group at the University of Freiburg, Germany.
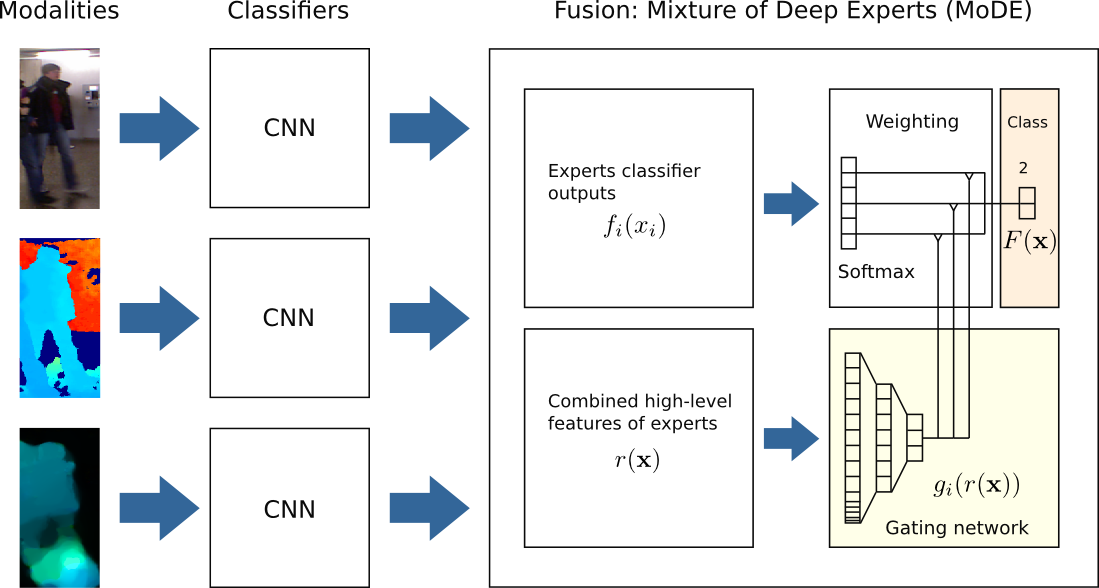
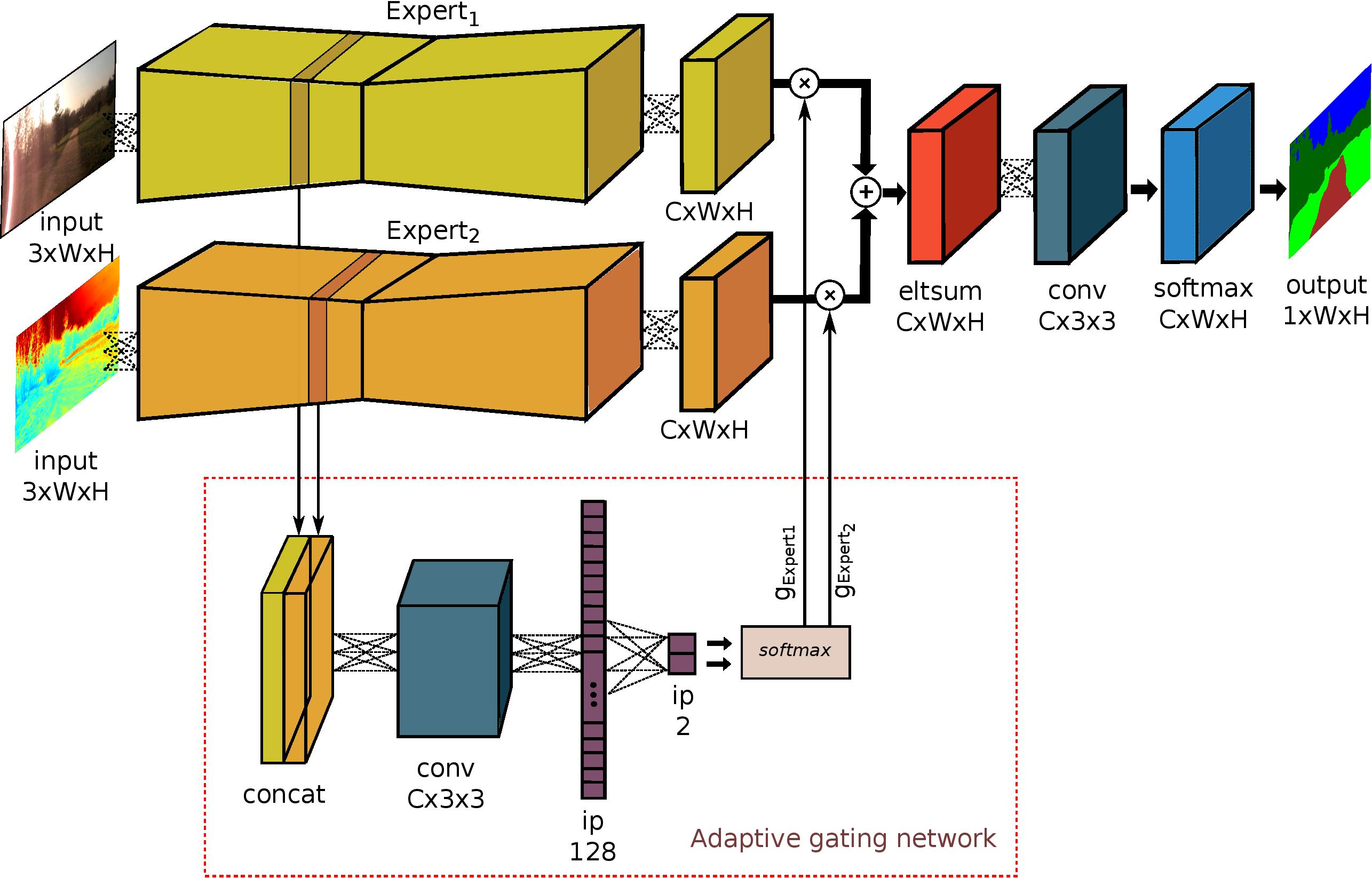
Our detection approach is based on a mixture of deep network experts (MoDE) that are fused in an additional gating network. The single experts are a downsampled version of Google's inception architecture. The fusion is learned in a supervised way, where the gating network is trained with a high-level feature representation of the expert CNNs. Thus, for each input sample, the gating network assigns an adaptive weighting value to each expert to produce the final classification output. The weighting is done individually for each detected object in the frame. In our IROS16 paper, we show results for RGB-D people detection in changing environments, but the approach can be extended to more sensor modalities and different architectures.
Mixture of Deep Experts For Semantic Segmentation
Our Mixture of Deep Experts approach can also be applied for semantic segmentation. In our ICRA17 paper and in the IROS16 workshop paper, a class-wise and expert-wise weighting is learned respectively. We show state-of-the-art segmentation results on a variety of datasets that contain diverse conditions including rain, summer, winter, dusk, fall, night and sunset. Thus, the approach enables a multistream deep neural network architecture to learn features from complementary modalities and spectra that are resilient to commonly observed environmental disturbances.
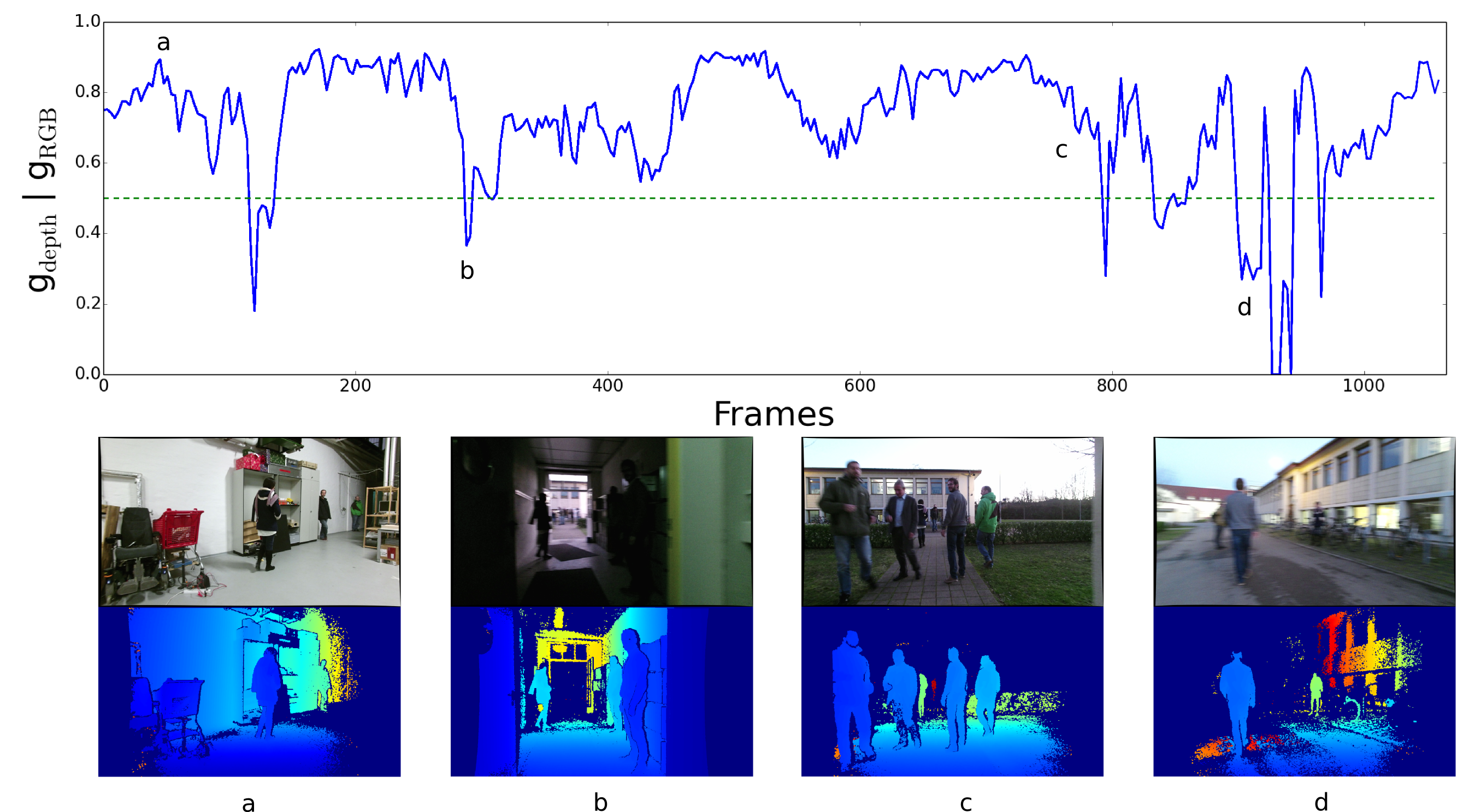
This dataset collection has been used to train deep neural networks for the task of people detection in RGB-D data. The approach is presented in our paper Choosing Smartly: Adaptive Multimodal Fusion for Object Detection in Changing Environments, which was published at IROS 2016.

The InOutDoorPeople dataset contains 8305 annotated frames (bounding boxes) of RGB and depth images in both 1920x1080 and 960x540 pixel resolution. The data was collected at a framerate of 30hz from a Kinect v2 camera, which was mounted on a mobile robot. A particularity of the recorded sequences is, that the robot was driving from indoor to outdoor environments in a single take. The dataset is subdivided into four sequences, two recorded during midday and the other two recorded at dusk.
Please cite our work if you use the InOutDoorPeople Dataset or report results based on it.
@InProceedings{mees16iros,
author = {Oier Mees and Andreas Eitel and Wolfram Burgard},
title = {Choosing Smartly: Adaptive Multimodal Fusion for Object Detection in Changing Environments},
booktitle = {IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)},
year = 2016,
month = oct,
url = {http://ais.informatik.uni-freiburg.de/publications/papers/mees16iros.pdf},
address = {Deajeon, South Korea}
}This program is provided for research purposes only. Any commercial use is prohibited. If you use the dataset, please consider citing our paper.
The dataset contains the rgb and depth data, together with the annotations and camera calibration file to create the original point clouds.



